In the recent communication with investors, we found that some investors have some differences on several key issues related to the big model, so this paper hopes to talk about our understanding on these issues.
Question 1: Which scenarios will be the potential application scenarios that we need to focus on?
Looking for the native application in the era of big model.At present, the way to find the landing scene of a large model in the market is basically based on the linear extrapolation of previous scenes, that is, "how to do what you can do better." But in fact, every technological innovation in the past eventually brought some "original" product forms and landing scenes. We believe that the greater value of the big model may lie in helping us solve some problems that could not be solved before (including those that could not be solved before due to technical or cost reasons). Just like the killer applications of the mobile Internet are "native" in the new era, not migrated from the PC Internet.

In the process of waiting for the big model business to land, we don’t have to be too pessimistic.There is no doubt that the commercial landing of any technology is not achieved overnight. Unlike some investors, the development of large models this month will directly generate income next month. In this process, the "slower than expected" of the big model actually comes from the change of our own mentality. As we often hear a saying: "When a technology is born, we tend to overestimate its short-term impact and underestimate its long-term impact." After the initial overexcitation, we are often too pessimistic about the landing prospect of technology.
In the report "What is the methodology for finding potential application scenarios of AI technology?",we have given the methodology to find the potential landing scene of AI, which will not be repeated here. Just make a supplementary discussion on an interesting question.
In the previous report, we divided the scenarios from two dimensions: "the size of business value" and "the difficulty of data acquisition", and pointed out that for general companies (compared with Internet giants such as BAT and vertical giants such as Iflytek), the potential opportunities may come from the long tail scenarios.
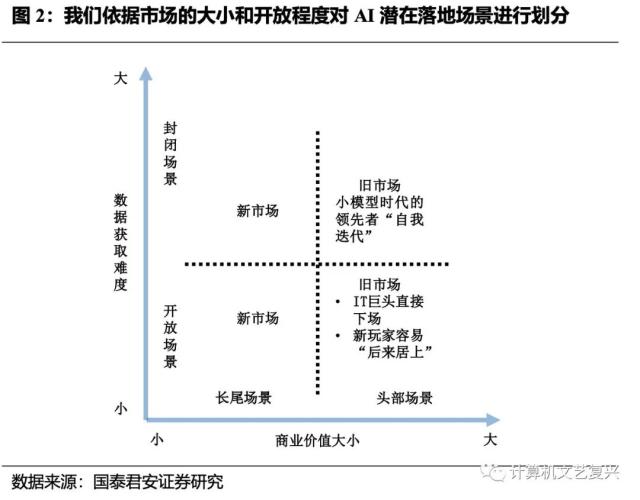
So what kind of scene is the better potential direction for the second quadrant, that is, the closed scene-long tail scene quadrant and the third quadrant, that is, the open scene-long tail scene quadrant? We think it is the second quadrant. The reason is:
The "closed" feature of the second quadrant means that data acquisition ability is more important than model ability, and the owners of channel and industry corpus will have a stronger voice.For an open scene, big model manufacturers have more say. In this kind of scenario, the "empowered enterprise" can maintain its competitiveness only by constantly generating new application ideas, otherwise it risks being eaten by large model manufacturers or facing homogenization competition of similar products in the market. It is obviously not easy to continuously generate new ideas.

Question 2: Is the main significance of the big model to improve the accuracy of problem solving?
Relatively speaking, improving the accuracy of solving single-point problems may be a "less important" improvement brought by large models.Because both the large model and the scene model are still based on the statistical framework, the unexplained problem of AI ability cannot be completely solved for the time being, which means that it will still be very limited in some sensitive scenes of corner case. Because in essence, this is a technical and ethical issue, and there is no essential difference between 98% accuracy and 95% accuracy in this kind of scene.
So, in addition to improving accuracy, what are the potential of large models?
First, the big model can help us solve some single-point problems that could not be solved before.This has been discussed above and will not be repeated here.
Second, the big model is expected to completely change the IT development paradigm and enhance the standardization of vertical products.In many vertical scenarios, although customers’ needs are generally similar, there are still some differences, such as customers’ own business processes, or the focus of IT construction. This leads to a lot of customization work when building IT capabilities for these customers, which greatly reduces the scale effect of IT vendors. With the landing of the big model, the data of subsequent customers may be connected to the big model through the plug-in mode, and the overall interaction of the front end can be realized directly through natural language, which means that the standardization of some vertical domain software is expected to be greatly improved.

Question 3: Does the "Thousand Models War" mean that every company can make a big model?
In recent exchanges with investors, we found a very interesting point: with more and more press conferences related to big models, some investors intuitively think that every company can make big models.
In our opinion, the situation is not what everyone thinks.There are still many barriers to building a good big model, including but not limited to:
Capital expenditure: This is the most obvious barrier.As we all know, training a large model with tens of billions of parameters requires hundreds of GPU cards, each of which is 70 thousand, which means that the cost of building a cluster is tens of millions to hundreds of millions of yuan. If you are training a model with hundreds of billions of parameters, you need a kilocalorie cluster. Obviously, not every manufacturer has the strength to invest in this area. Moreover, the call of cloud resources in the training process will also consume a lot of costs.
Engineering ability:At present, the research foundation of GPT series models is mainly based on a paper by Open AI on Instruct GPT. In GPT-3, instruction GPT and previous versions, Open AI is completely open source for GPT technology, and the published papers are very detailed, including the idea of making GPT model, what data set is used and so on. However, since the Da Vinci model (Code-Davinci-002, around Q1, 2022), the GPT series has moved towards a closed source. Technically speaking, Open AI has disclosed its main ideas before, so why haven’t other manufacturers achieved a complete re-enactment yet? One of the important reasons is that Open AI does not disclose its data engineering information, such as how to obtain data, how to do data training, how to feed it into the model and so on. Therefore, although the model itself is not so strong, how to train and process data contains a lot of technological skills, which is the engineering ability we often mention.
Question 4: Will the trend of "technology popularization" brought by the big model make the leading players in the scene model era be quickly subverted?
We don’t think so.
From a technical point of view, "model fine-tuning" actually includes two connotations.
The first layer is to use SFT data to do fine-tune, where SFT data are those question-and-answer pairs. In this process, what the model acquires is actually not the in-depth knowledge of a certain industry, but a kind of answer mode that is more in line with human expectations. In this process, the number of question-and-answer pairs we need is often not very large. According to the results of our industry research, training a brand-new ability basically requires only a thousand questions and answers.
The second layer is in the process of pre-training, feeding a large number of corpus of an industry to further train the model. In this process, in order to make the model master the industry knowledge in this field, we need to feed a large number of corpus in the corresponding field for training, and at the same time, we need to ensure the quality of the fed corpus, otherwise it will also affect the effect of model distillation.
"Model distillation" still needs a certain volume of industry data.According to the results of our industry research, it is necessary to use the above two methods at the same time in order to obtain better results in the process of "distilling" large models into industry models. This means that the process of "model distillation" will still have a large demand for industry data.
Obviously, not every industry corpus is easy to obtain.In our previous report, this problem was attributed to the problem of "scene openness" (see the report "Digital Compass in the Age of AI Navigation" for details), and we will only make a brief statement here.
In the open scene, the data needed for "model distillation" can be obtained by public means.Including various applications derived from traditional or emerging consumer electronics items, such as ecological software on mobile phones, software on smart speakers and so on. These are typical "open scenes". After the user uses a product, the data is directly deposited in the product terminal or background.
In a closed scene, data is deeply bound to a specific type of mechanism, and the data needed for "model distillation" is not easy to obtain. Data and channels are more important than the model capability itself.2B or 2G, many subdivided tracks are "closed scenes", such as medical care, education, politics and law, industry and so on. In this kind of scenario, data is deeply bound to a specific type of institution, so that it is very difficult for new entrants to obtain data, and it is difficult to build a trust relationship with customers in a short time. "Data acquisition ability and channel advantages" dominate, and the leaders in the small model era have a higher probability of using large models to achieve "self-iteration".
Question 5: What are the advantages of a company with both large model and vertical scene data?
When we discuss the empowerment of the big model to the industry, we naturally divide the company into two categories: big model manufacturers and empowered manufacturers. However, we believe that companies with large models and numerous vertical scene data may be more scarce, and their competitive advantages come from at least the following aspects:
First, the advantage of cooperation.
We believe that although the big model is still in the stage of "thousand-model war", with the passage of time, most manufacturers will withdraw from the competition, and the big model will eventually remain a game of giants. This means that there are not many large models that can be selected in the end.
At this stage, large model manufacturers have established many barriers such as ecology, technology and cost, and the right to speak has risen accordingly. In this case, it is unrealistic for a specific vertical customer to expect large model manufacturers to "distill" and train their models.
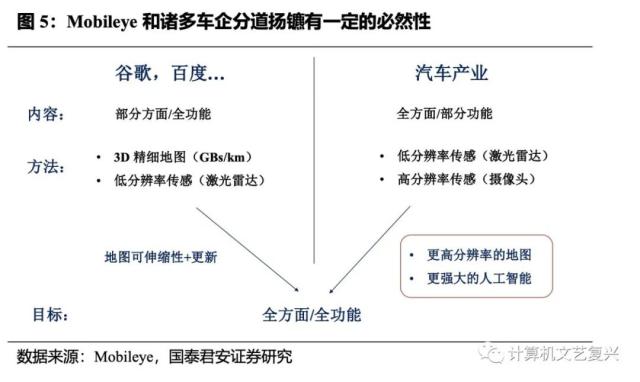
Here, an example of the autonomous driving industry can be introduced for analogy. In the era of ADAS, Mobileye occupies the vast majority of the world’s share, which means that it needs to serve many OEMs around the world at the same time, and it is difficult to cooperate with each OEMs in time and effectively, both subjectively and objectively. It can be said that Mobileye has gradually declined in recent years because of its strength in the last stage.
At this time, for companies with both large models and vertical industry scenes, the cooperation between the two teams belongs to the internal resource scheduling of the company, and the difficulty of resource allocation is obviously smaller.
Second, the advantages of iterative efficiency.In the process of distilling the large model to obtain the industrial model, there is a certain degree of "coupling" between the large model and the industrial model. That is to say, when the basic big model is updated, if the industry model is not iterated again, the final effect may be worse in turn due to the upgrade of the big model. For companies with both large models and vertical industry scenarios, it has obvious advantages in iterative efficiency.
Third, the advantages of differentiated competition.There is a saying often mentioned by investors: "When all companies benefit, it means that no company may really benefit." In the initial stage, the comparison of product competitiveness of different companies in a vertical scene may change because of their different acceptance and access speed to the big model. However, in the long run, the influence of big models on the industry structure may tend to weaken when the technology of several big model manufacturers who finally win is not replaced by others. That is, the ultimate beneficiaries may be large model manufacturers and end consumers, but vertical manufacturers may not necessarily benefit from business. For companies with both large models and vertical industry scenarios, there will be no need to face the problem of homogenization competition.
This article comes from: Selected research reports of securities firms.
Authors: monarch computer Li Muhua and Qi Jiahong